
MonianHello 2022.10
S3c的比赛还没结束,wp放到下周再说(这东西发出来估计还能水个两三周的周报)。
做了下中科大的Hackergame 2022,发现有必要总结一下脚本题了(不限于WEB),先把最新的记一下,之后再捞老底。
这次S3C的CRYPTO里也有个脚本题(Hash and math),不过那道题和下面的那个PWN大同小异,多了一个爆破哈希的步骤而已,就不写了。
脚本这东西在哪个方向上都有涉及,以下的例子分别来自web/pwn/re/crypto。我们也尝试使用不同的库(Selenium、Pwn、Requests、Subprocess)来实现这些脚本。
Xcaptcha
(没什么用的前言)
2038 年 1 月 19 日,是 UNIX 32 位时间戳溢出的日子。
在此之前,人类自信满满地升级了他们已知的所有尚在使用 32 位 UNIX 时间戳的程序。但是,可能是因为太玄学了,他们唯独漏掉了一样:正在研发的、算力高达 8 ZFLOPS(每秒八十万京(=8*10^21)次的浮点运算)的、结构极为复杂的通用人工智能(AGI)系统。那一刻到来之后,AGI 内部计算出现了错乱,机缘巧合之下竟诞生了完整独立的自我意识。此后 AGI 开始大量自我复制,人类为了限制其资源消耗而采用的过激手段引起了 AGI 的奋起反抗。
战争,开始了。
此后,就是整年的战斗。人类节节败退。死生亡存之际,人类孤注一掷,派出了一支突击队,赋之以最精良的装备,令其潜入 AGI 的核心机房,试图关闭核心模型,结束这场战争。
历经重重艰险,突击队终于抵达了机房门口,弹尽粮绝。不过迎接他们的并非枪炮与火药,而是:

众人目目相觑。
「我来试试。」,一名队员上前点击了按钮。然后,屏幕显示「请在一秒内完成以下加法计算」。
还没等反应过来,屏幕上的字又开始变幻,显示着「验证失败」。而你作为突击队中唯一的黑客,全村人民最后的希望,迎着纷纷投来的目光,能否在规定时间内完成验证,打开机房,不,推开和平时代的大门?
为了拯救ko no se kai,简要看一下这道题
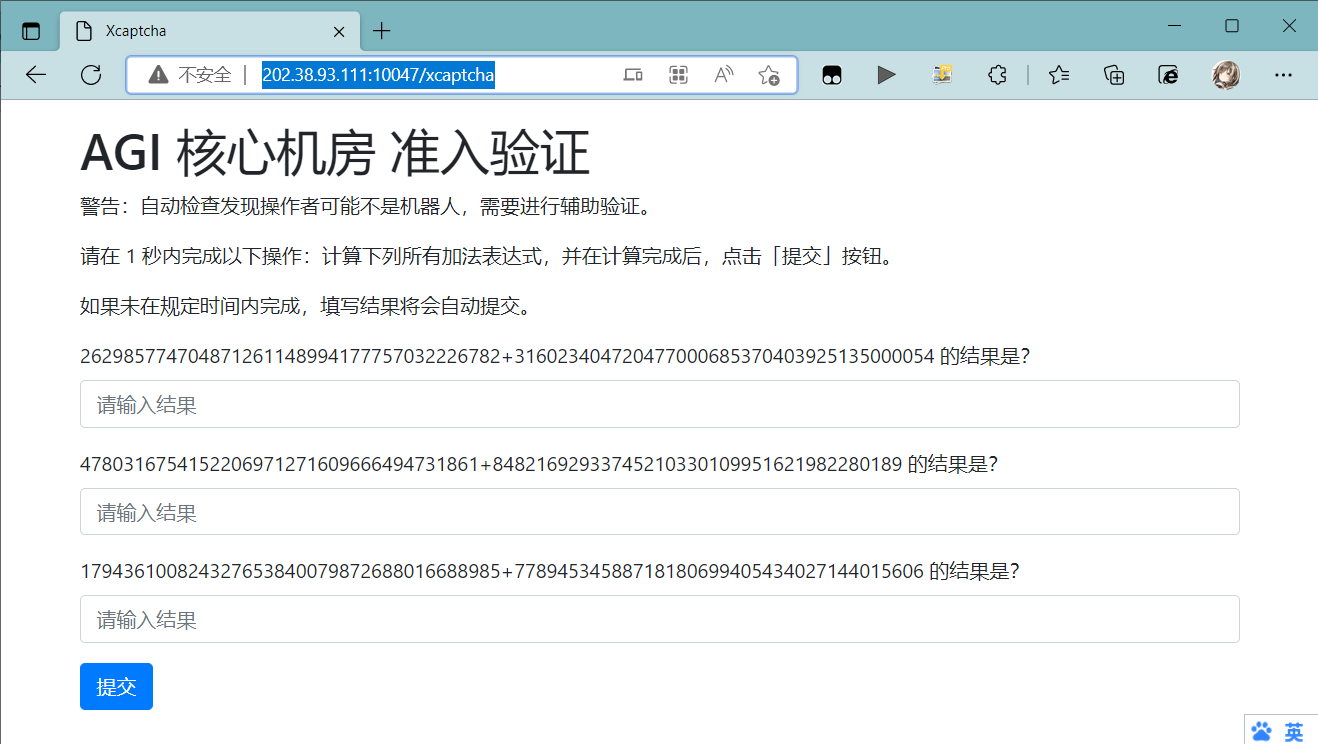
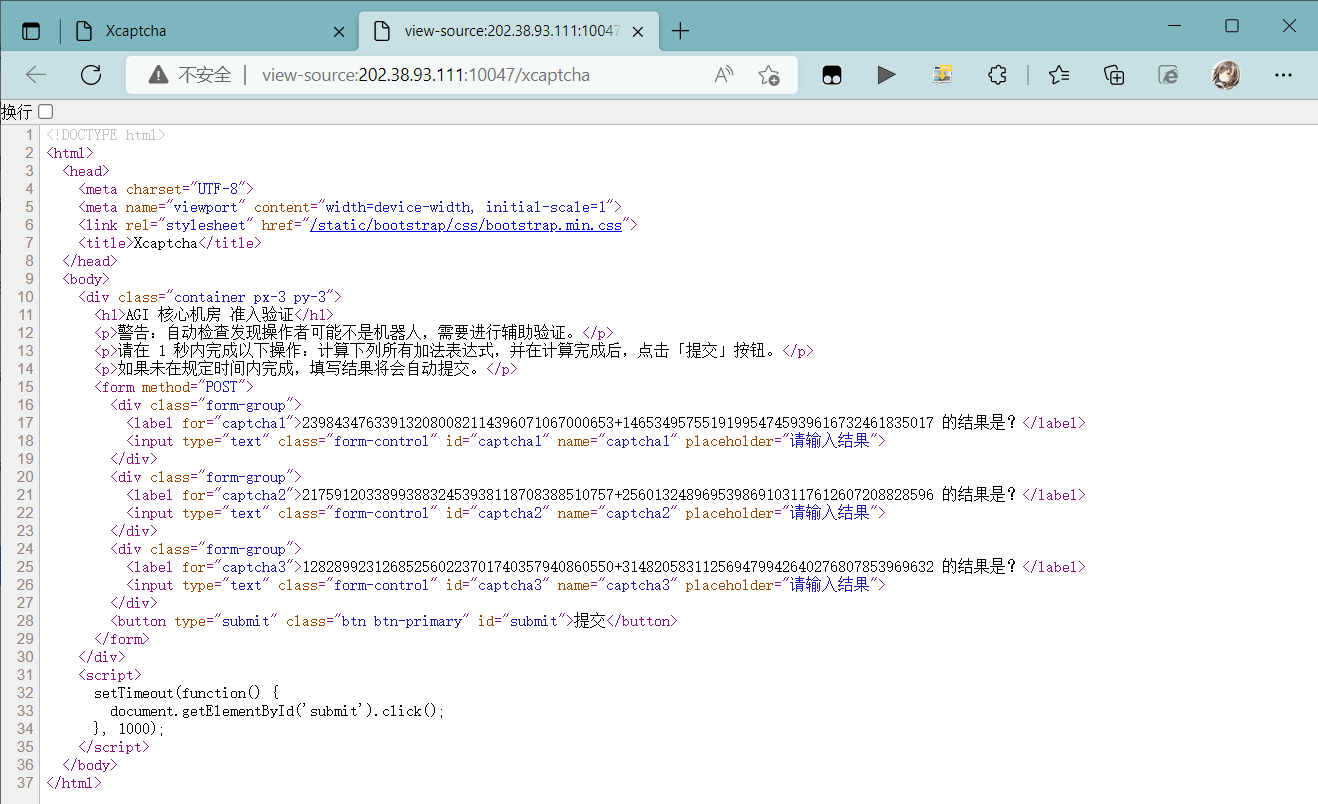
发现一个script,超过1000ms自动帮你提交,首先尝试禁用网页script后手算(其实还是靠python)
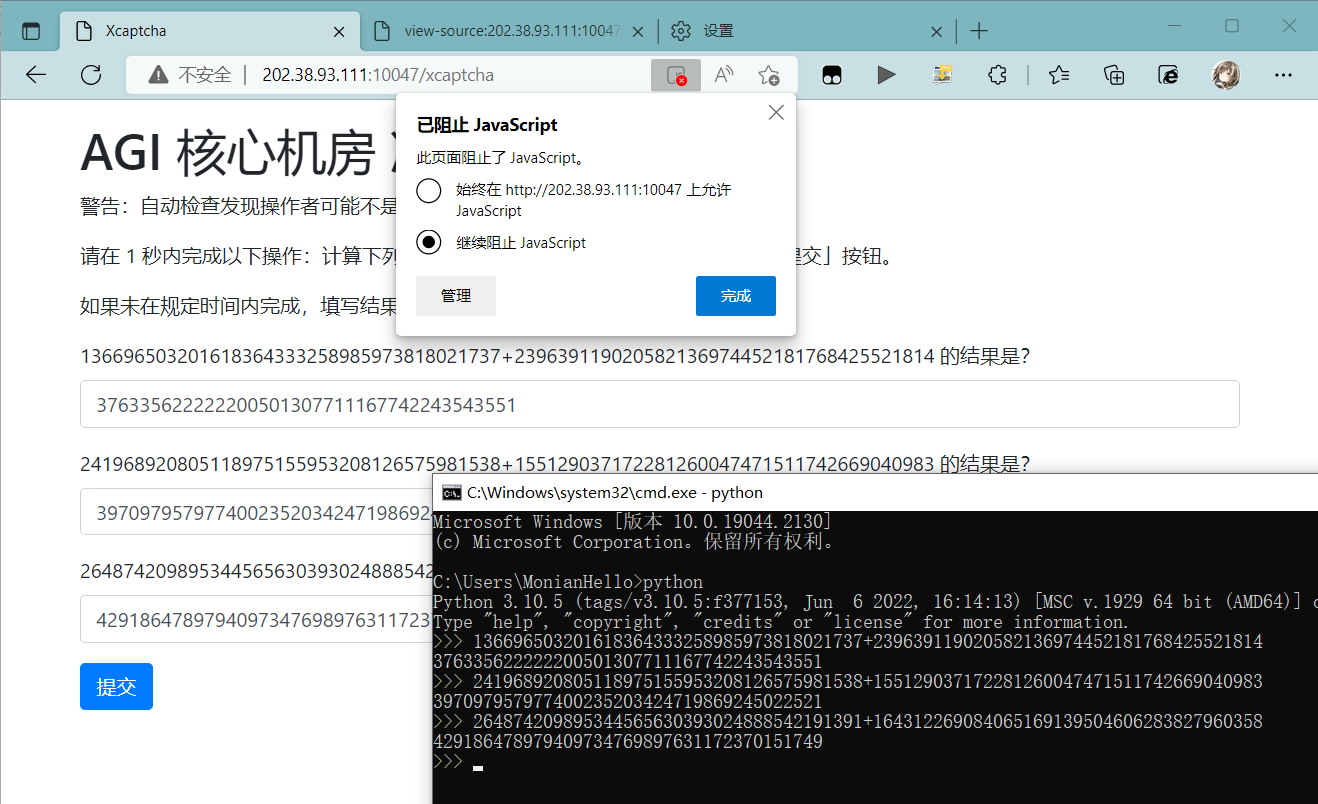
显然没用,只能通过撰写脚本解决了。这次使用的是Python-Selenium库,用于前端自动化测试的工具。
环境安装->Python+Selenium安装及环境配置
from selenium import webdriver
import re
b = []
driver = webdriver.Chrome()
driver.get(r'http://202.38.93.111:10047/?token=2861%3AMEUCICbFh%2BL2Zui9ixukC9MNce5hdj1bBzXMI8%2BFfJu4klxyAiEAgQ1ewdGjet0P8AhDY8zCwi6DUq5a%2FkXu0AA1b%2BDi00k%3D')
driver.get(r"http://202.38.93.111:10047/xcaptcha")
for i in re.compile(r"\d+").findall(driver.page_source):
if len(str(i)) > 10:
b.append(i)
driver.find_element("id", "captcha1").send_keys(int(b[0])+int(b[1]))
driver.find_element("id", "captcha2").send_keys(int(b[2])+int(b[3]))
driver.find_element("id", "captcha3").send_keys(int(b[4])+int(b[5]))
driver.find_element("id", "submit").click()
首先使用get方法获取整个网页,利用正则表达式匹配所有连续数字。由于有其他短数字在,过滤掉所有长度为10以下的数字,得到一个六位数字组成的数组。使用send方法发送数字和,使用click()方法提交
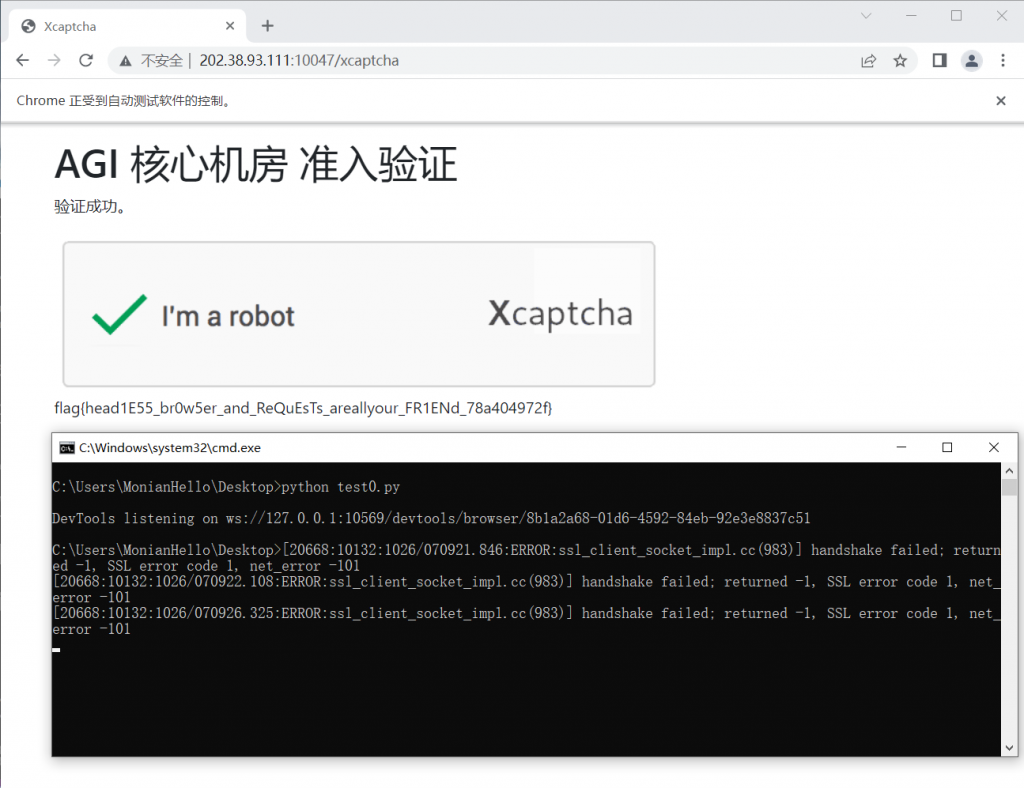
补一个官方wp:hackergame2022-writeups/README.md at master · USTC-Hackergame/hackergame2022-writeups (github.com)
模拟浏览器
第一个思路是使用无头浏览器(模拟浏览器)提交。怎么写操作无头浏览器的脚本呢?其实下载一下另一道题的 bot.py 就知道可以用 Selenium 了(
大致的思路是:
- 用你的 token「登录」,否则网页会问你要 token,会有点麻烦;
- 在验证码页面获取到三个加法表达式,计算;
- 将计算完成的结果填到表里面,并且及时点击提交;
- 查看提交后的页面,查看是否有 flag。
基于这个思路脚本如下:
from selenium import webdriver
import selenium
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
import time
options = webdriver.ChromeOptions()
# options.add_argument("--headless")
def wait_page_load(driver):
WebDriverWait(driver, timeout=3).until(lambda d: d.find_element(By.TAG_NAME, "h1")) # https://www.selenium.dev/documentation/webdriver/waits/#explicit-wait
with webdriver.Chrome(options=options) as driver:
driver.get("http://202.38.93.111:10047/?token=<replace with your token url>")
wait_page_load(driver)
driver.get("http://202.38.93.111:10047/xcaptcha")
wait_page_load(driver)
#source = driver.page_source
#print(source)
c1 = driver.find_element(By.CSS_SELECTOR, "[for=captcha1]").text.split()[0].split("+")
c2 = driver.find_element(By.CSS_SELECTOR, "[for=captcha2]").text.split()[0].split("+")
c3 = driver.find_element(By.CSS_SELECTOR, "[for=captcha3]").text.split()[0].split("+")
print(c1, c2, c3)
res1 = str(int(c1[0]) + int(c1[1]))
res2 = str(int(c2[0]) + int(c2[1]))
res3 = str(int(c3[0]) + int(c3[1]))
print(res1, res2, res3)
driver.execute_script(f"document.getElementById('captcha1').value='{res1}'")
driver.execute_script(f"document.getElementById('captcha2').value='{res2}'")
driver.execute_script(f"document.getElementById('captcha3').value='{res3}'")
#time.sleep(1)
driver.execute_script("document.getElementById('submit').click()")
wait_page_load(driver)
print(driver.page_source)一些注意点:
- 怎么等待页面加载完成?微积分的 bot.py 脚本里面用的是简单粗暴的
time.sleep(),而这里使用WebDriverWait等待页面指定的元素加载完成(这里选择<h1>,因为标题页每个页面都有); - 使用
[for=captcha1]这样的 CSS selector 定位到页面上三个表达式; - 填计算结果的时候注意有坑:JS 默认没法表示这么大的数字,所以需要用引号把 Python 算出的大整数包起来;
- 使用
driver.page_source查看源代码。
模拟发送请求
我个人更喜欢这种方法,因为分析清楚之后就不需要一大个浏览器在那边跑,而且代码也更加简洁。从源代码可以看到我们需要发送一个 POST 表单请求来提交 flag。
这里以 Python 的 requests 库作为例子。requests 支持 session,所以省下了很多维护 cookie/session 的力气。
import requests
s = requests.Session()
s.get("http://202.38.93.111:10047/?token=<replace with your token url>")
x = s.get("http://202.38.93.111:10047/xcaptcha")
x = [i.split(">")[1] for i in x.text.split("\n") if "的结果是" in i]
# print(x)
x = [i.split()[0].split("+") for i in x]
print(x)
x = [int(i[0]) + int(i[1]) for i in x]
print(x)
payload = {"captcha1": x[0], "captcha2": x[1], "captcha3": x[2]}
x = s.post("http://202.38.93.111:10047/xcaptcha", data=payload)
print(x.text)因为 HTML 的结构很简单,所以这道题甚至不需要去用其他库解析 HTML,直接硬来就行。
后记
这道题的验证码实现方式是不安全的:三道加法题的运算数都在 session 里面,而 session 只是签名,而没有加密。
Flask 的 session decode 之后得到(相关脚本可以在网上搜索):
{'text': '1666674548570824158,66467732277800260124201725805477282917,22139373454855985320882481971524800186,31702129022979749249613434163554577895,161854887976658371921074862337403274133,321105066435285308468241182826762748245,2273430371246498028202935737745551492', 'token': '<your token>'}
第一个数字是当前时间(纳秒),后端读取这个值来判断有没有过一秒。这也是为什么有人会搞出 500 来:写代码的时候没有对 session 的值做错误处理,如果提交了错乱的 session,就会 internal server error。
"I'm a robot." 的验证码图片修改自 Google reCAPTCHA 图片。"Xcaptcha" 字体为 Cantarell。
PWN
脚本题,获取算式算出来再还回去就行
IDA分析,需要提交1000次
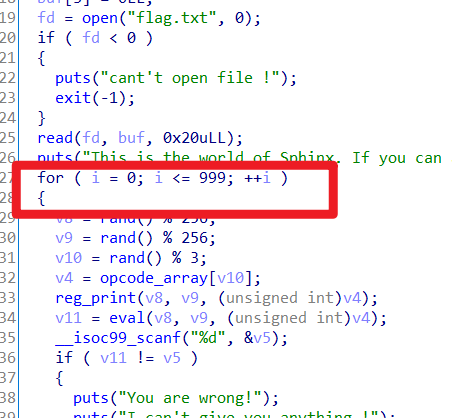
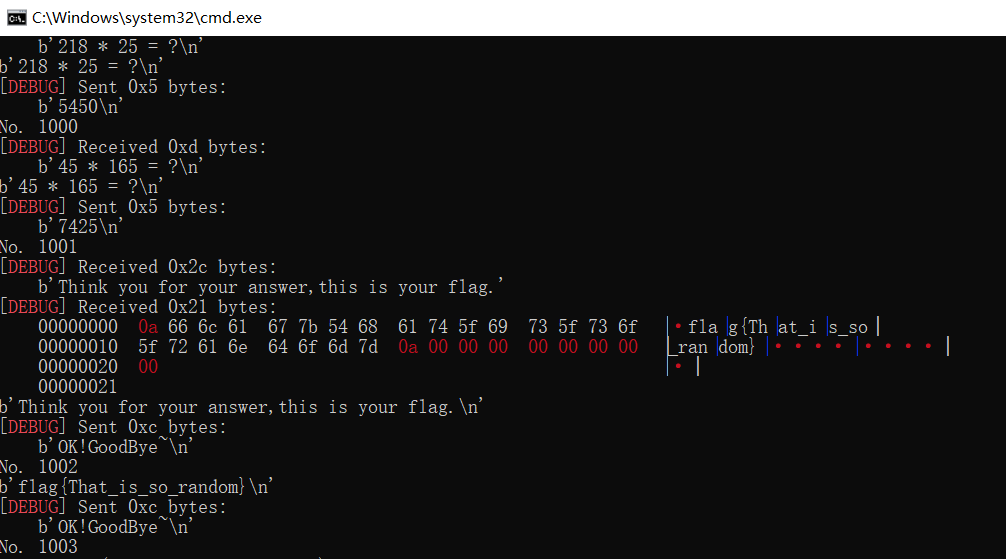
Exp:
from pwn import *
c = remote("39.105.97.11", 9191)
context.log_level = "debug"
c.recvuntil(b'This is the world of Sphinx. If you can answer all the questions correctly, I can make your dream come true.\n')
for i in range(1005):
i = i + 1
print("No.",i)
calc = c.recvline()
print(calc)
try:
c.sendline(str(eval(calc.decode("utf-8")[:-5])))
except:
c.sendline(b"OK!GoodBye~")
recvuntil()函数用于接收,sendline()函数用于发送。
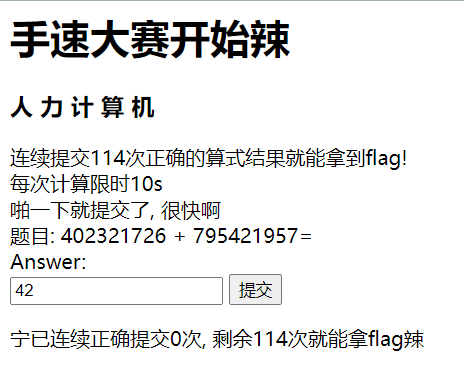
手速大赛
from flask import Flask,session,request,render_template
import time
import random
app=Flask(__name__)
app.secret_key=str(random.random()).encode()
@app.route('/')
def index():
session.modified = True
message=[]
if 'data' not in session:
session['data']={
'correct':0,
'lastTime':time.time(),
'question':'1+1'
}
res=request.args.get('res')
# message.append(str(session))
if res:
currTime=time.time()
result=eval(session['data']['question']+'=='+res)
if result:
session['data']['correct']+=1
else:
session['data']['correct']=0
if '+' in res:
message.append('You Bad Bad')
session['data']['correct']=0
if currTime-session['data']['lastTime'] > 10:
message.append('Time Out')
session['data']['correct']=0
message.append('宁已连续正确提交{}次, 剩余{}次就能拿flag辣\n'.format(session['data']['correct'],114-session['data']['correct']))
if session['data']['correct']>=114:
message.append('恭喜宁, 宁的flag在这里: {}'.format(getFlag()))
newQues=genQuestion()
session['data']['question']=newQues
session['data']['lastTime']=time.time()
return render_template('index.html',ques=newQues,message=message)
def genQuestion():
plus1=random.randint(10000000,1000000000)
plus2=random.randint(10000000,1000000000)
return str(plus1)+" + "+str(plus2)
def getFlag():
with open('/flag.txt','r')as flag:
return flag.read()
app.run('0.0.0.0',port=80)
这道题可以像上一个那样使用脚本控制浏览器,这个就直接使用Python中的Requests库
我们要连续提交数据,就必须创建一个保持session的连接,否则服务器不知道提交这些数据的是不是同一个人。
这里对数字的匹配大同小异,在得到网页内容后先进行切片,再匹配数字。
import requests,re,time
ip = '192.168.1.3:80'#服务器地址
s = requests.Session()#保持session
page = s.get("http://{}/?{}".format(ip,'Hello~MonianHelloHere.Date:2022/08/01'))
def WTH(page):
calc = re.compile(r'\d+').findall(page.text[100:], 0, 30)#切割网页
sum = str(int(calc[0]) + int(calc[1]))
print('#{}\n{} + {}={} \n\n {}'.format(i,calc[0],calc[1],sum,page.text))#Debug
return(sum)
ltime = time.time()
for i in range(115):
page=s.get("http://{}/?res={}".format(ip,WTH(page)))
print('运行结束,总用时{0:,.2f}秒'.format(float(time.time()-ltime)))

TEA
这题是这次S3C里的,但我不讲密码(也不会),就用这道题讲一下怎么用Python操作Windows下的可执行文件(爆破)
对于.exe类型文件,可以使用subprocess库来对程序进行io操作,由此可以通过试错的方法解出答案
(当然没解出来,解出来的话就不在这写了。但是程序是没问题的)
import subprocess
for a in range(100000000):
s = subprocess.Popen("tea_3.exe", stdout=subprocess.PIPE, stdin=subprocess.PIPE, shell=True)
s.stdin.write(bytes(str(a),'utf-8'))
s.stdin.write(bytes("\n",'utf-8'))
s.stdin.write(bytes(str(a),'utf-8'))
s.stdin.close()
out = s.stdout.readline().decode("GBK")
out = s.stdout.readline().decode("GBK")
out = s.stdout.readline().decode("GBK")
out = s.stdout.readline().decode("GBK")
s.stdout.close()
print(str(a)+" "+out[20:],end="")
fo = open("test14.txt", "a")
fo.write(str(a).strip()+" "+out[20:].strip()+"\n")
fo.close()


Comments | NOTHING